数据结构 基础查找
基本概念
静态查找
数据集合稳定,不需要添加,删除元素的查找操作
动态查找
在数据集合进行查找的过程中,需要同时添加或删除元素的查找操作
关键字
数据元素中某个项的值,用它可以唯一标识一个数据元素
内查找和外查找
若整个查找过程都在内存中进⾏,则称之为内查找(internalsearch);
反之,若查找过程的需要访问外存,则称之为外查找(external search)。
平均查找⻓度(Average Search Length,ASL)

注:ASL是衡量查找算法性能好坏的重要指标。
⼀个査找算法的ASL越⼤,其时间性能越差;
反之,⼀个查找算法的ASL越⼩,其时间性能越好。
线性查找:顺序查找 二分查找 分块查找——>静态查找 注:以上均基于比较查找 1.顺序查找 从表中的第⼀个(或者最后⼀个)记录开始,逐个进⾏记录的关键字和给定值的⽐较, 若某个记录的关键字和给定值⽐较相等,则查找成功。 如果查找了所有的记录仍然找不到与给定值相等的关键字,则查找不成功。
时间复杂度:O(n)
2.二分查找----前提,数据有序存放,存放在数组中(链表不适合)
确定待查记录所在的范围(区间),然后逐步缩⼩范围直到找到或者找不到该记录为⽌。
注意⼆分查找是在有序表上进⾏的,且⼆分查找也是分治思想的很好例证。
时间复杂度:O(logn)
判定树:
折半查找过程可⽤⼆叉树来描述,把当前查找区间的中间位置上的元素作为根,
由左⼦表和右⼦表构造的⼆叉树分别作为根的左⼦树和右⼦树,由此得到的⼆叉树称为描述折半查找过程的判定树
(deecision tree)或⽐较树(comparison tree)。
注:显然,判定树是⼀棵平衡⼆叉树,反之不成立
3.分块查找
索引存储结构
索引存储结构是在存储数据的同时还建⽴附加的索引表。索引表中的每⼀项称为索引项,索引项的⼀般形式为(关键字,地址)。
其中,关键字唯⼀标识⼀个结点,地址作为指向该关键字对应结点的指针,也可以是相对地址(如数组的下标)。
将査找表分为若⼲⼦块。块内的元素可以⽆序,但块之间是有序的,即第⼀个块中的最⼤关键字
⼩于第⼆个块中的所有记录的关键字,第⼆个块中的最⼤关键字⼩于第三个块中的所有记录的关键字,以此类推。
再建⽴⼀个索引表,索引表中的每个元素含有各块的最⼤关键字和各块中的第⼀个元素的地址,索引表按关键字有序排列。
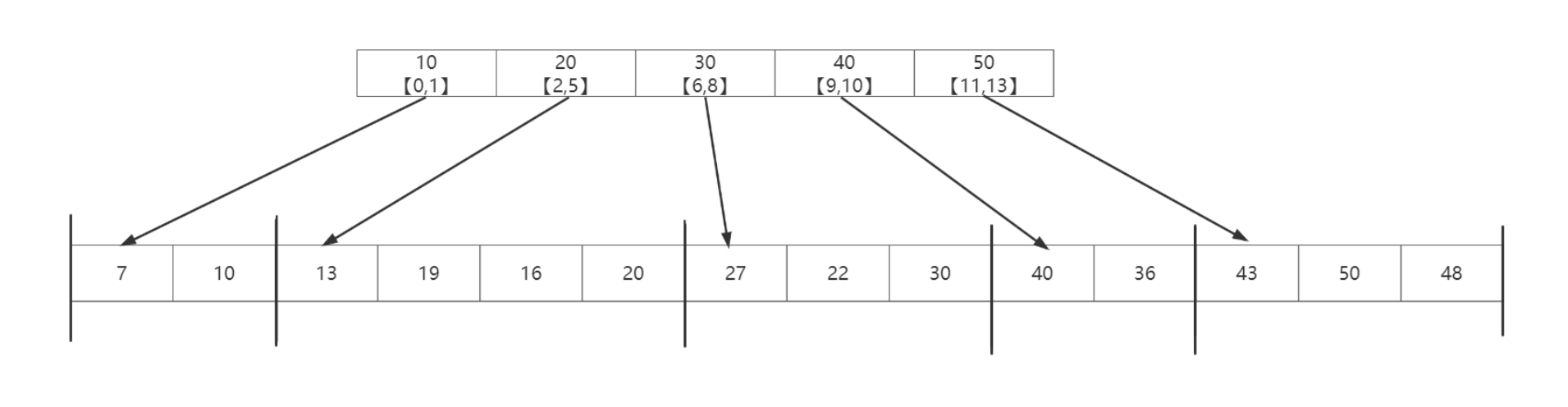 分块查找步骤
分块查找的过程分为两步:
第⼀步是在索引表中确定待查记录所在的块,可以顺序查找或折半査找索引表;
第⼆步是在块内顺序查找。
分块查找步骤
分块查找的过程分为两步:
第⼀步是在索引表中确定待查记录所在的块,可以顺序查找或折半査找索引表;
第⼆步是在块内顺序查找。
基于散列表的查找:哈希——>动态查找 注:散列存储也叫hash存储 哈希查找—散列查找—–>散列存储
哈希: key —–> 哈希函数 ——> Add(地址) 冲突:两个不同数据,计算出同一个地址 哈希函数如何设计 1.直接定址法:哈希函数设计为一次函数 h(key)=a*key+b 优点:不产生冲突 缺点:空间浪费大 2.除留余数法:哈希函数设计为对一个质数取余 h(key)=key%p p<=m的质数,m是散列表大小 缺点:冲突几乎必然存在,只能尽可能降低 3.平方取中法 4.数字分析法 5.折叠法
冲突解决方式
1.开放地址法:保证所有数据都存放在哈希表中
当产生冲突时,去计算一个偏移量d,结合d重新计算一个地址
1.线性探测法:d=1,2,3......
2.平方探测法:d=1^2,-1^2,2^2,-2^2......
3.双重哈希法/双散列法:d = h2(key) * i
h(key)=( h(key) + h2(key) * i) % m 注:m为散列表大小
4.伪随机序列法 d=随机序列
2.链地址法
将产生冲突的数据用单链表串起来,挂在同一个地址处
1.ASL 平均查找长度
2.装填因子 a(阿尔法)=表中数据的实际数量/哈希表长度 保持在0.75及以下
3.再哈希:对哈希表进行扩容,对数据再次哈希算新地址放到新的哈希表中
哈希的应用
1.哈希查找
2.密码校验